| |
Praktische Datenanalyse mit R (R Grundkurs)
- Termin:
- Do 8.11.2007, 9-17:30 & Fr 9.11.2007, 9-16
- Dozenten:
- Prof. Dr.
Torsten Hothorn, Prof.
Dr. Friedrich Leisch
- Voraussetzungen:
- Kenntnisse in Statistik im Umfang einer
Einführungsvorlesung
Inhalt:
Dieser Grundkurs richtet sich an Anfänger, die das Werkzeug R
zur
Analyse und Visualisierung eigener Daten erlernen wollen. Neben
Installation und Grundlagen der Bedienung von R wird die praktische
Anwendung statistischer Methoden (im Umfang einer typischen
Einführungsvorlesung aus Statistik) an Beispielen demonstriert
und
geübt. Der Kurs umfasst die Themen:
- Grundlagen von R, Installation des Basispakets und
von Erweiterungspaketen
- Datenimport und Datenmanipulation
- Berechnung von Kennzahlen: Mittelwert, Varianz,
Median, Quantile, Häufigkeitsverteilungen, Kontingenztafeln,
...
- einfache Grafiken: Histogramme, Boxplots,
Dichteschätzer, Balken- & Streudiagramme, ...
- Klassische Inferenzstatistik: t-Test, F-Test,
Chi-Quadrat-Test, ...
Alle verwendeten statistischen Verfahren werden zur
Auffrischung kurz erklärt. Der Kurs basiert auf dem Buch
A Handbook of Statistical Analysis Using R von Brian S.
Everitt
und Torsten Hothorn, erschienen 2006 bei CRC Press (ISBN
9781584885399). Ein Freiexemplar des Buches ist in der
Kursgebühr enthalten.
Programmieren mit R
- Termin:
- Do 13.12.2007, 9-17:30 & Fr 14.12.2007, 9-16
- Dozenten:
- Prof. Dr.
Torsten Hothorn, Prof.
Dr. Friedrich Leisch
- Voraussetzungen:
- elementare Kenntnisse in Statistik, praktische
Erfahrung in der Anwendung von R zur Analyse von Daten (etwa im Umfang
des Grundkurses)
Inhalt:
Statistik wird in immer größerem Ausmaß zu
einer computationalen
Wissenschaft, inbesonders die angewandte Statistik kommt ohne den
Einsatz
und die Beherrschung moderner Software-Werkzeuge nicht aus. Dieser
Kurs dient der allgemeinen Vertiefung in die Datenanalyse mit R und
richtet sich an Teilnehmer, die bereits erste Erfahrungen mit R
gesammelt haben (z.B. im Grundkurs, oder auch im
Selbststudium). Aufbauend auf grundlegenden R-Kenntnissen werden
einfache Programmiertechniken vermittelt, mittels derer sich das
komplexe Werkzeug R leichter bedienen lässt:
- Effizienter Umgang mit R
- Grundlegende Elemente und Prinzipien der Sprache
- Schreiben eigener Funktionen
- Tipps und Tricks zu gutem Programmierstil, gute
Programmierpraktiken
- Hilfswerkzeuge: Laufzeitanalyse, Debugging, Exception
Handling, ...
- Objektorientierte Programmierung
- Implementierung eigener statistischer Modelle in R
Machine Learning & Data Mining mit R
- Termin:
- Do 24.1.2008, 9-17:30 & Fr 25.1.2008, 9-16
- Dozenten:
- Prof. Dr.
Torsten Hothorn, Prof.
Dr. Friedrich Leisch, Carolin
Strobl M.Sc.
- Voraussetzungen:
- elementare Kenntnisse in Statistik, praktische
Erfahrung in der Anwendung von R zur Analyse von Daten (etwa im Umfang
des Grundkurses)
Inhalt:
In diesem Kurs werden moderne statistische Verfahren des maschinellen
Lernens zur Analyse komplexer Klassifikations- und Regressionsprobleme
vorgestellt, die besonders für die Modellierung nicht-linearer
Regressionszusammenhänge in hoch-dimensionale Daten geeignet
sind. Die zugrundeliegenden Prinzipien der Verfahren werden
verständlich eingeführt und illustriert, sowie
Besonderheiten
herausgehoben.
Ein Schwerpunkt ist dabei die Selektion von wenigen
relevanten
Einflußgrößen aus tausenden von
potentiellen
Kandidaten, z.B. in der Selektion von genetischen Markern zur Prognose
des Krankheitsstatus. Der Hauptteil des Kurses beschäftigt
sich
mit der Anwendung von in R verfügbaren Werkzeugen anhand von
Beispielen aus der Praxis.
- klassische und moderne Klassifikations- und
Regressionsbäume
- Bagging und Random Forests zur Prädiktion
und Variablenselektion
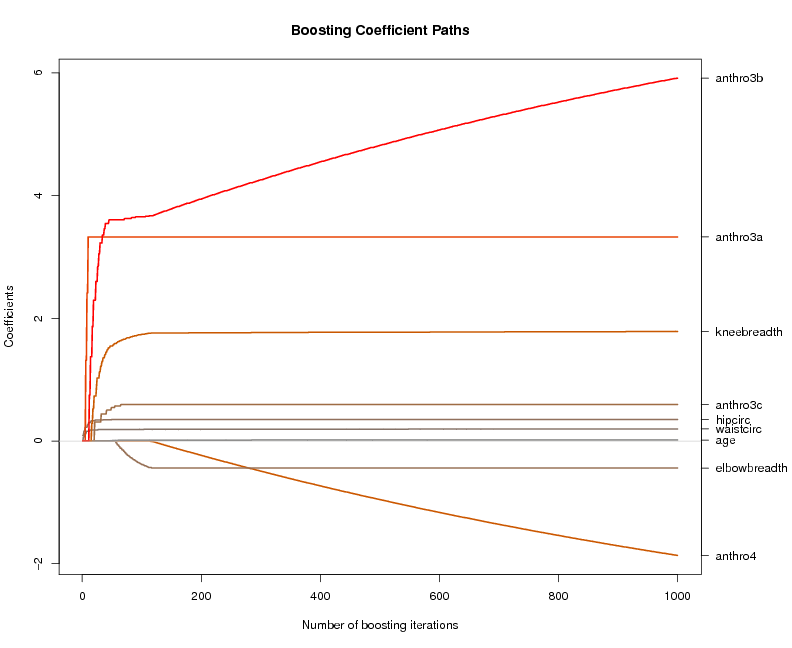
- Boosting von additiven und hoch-dimensionalen
generalisierten linearen Modellen
- Support Vector Machines
 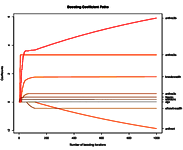
Generalisierte Regression mit R
- Termin:
- Do 24.4.2008, 9-17:30 & Fr 25.4.2008, 9-16
- Dozenten:
- Dr.
Thomas Kneib, Dipl.-Stat.
Fabian Scheipl
- Voraussetzungen:
- Grundkenntnisse zu linearen Modellen, praktische
Erfahrung in der Anwendung von R zur Analyse von Daten (etwa im Umfang
des Grundkurses)
Inhalt:
Dieser Kurs stellt nach einer kurzen Wiederholung des klassischen
linearen Regressionsmodells drei wesentliche Erweiterungen
vor:
- Generalisierte lineare Modelle:
- Die Zielvariable wird nicht mehr als (approximativ)
normalverteilt betrachtet, sondern folgt einer beliebigen Verteilung
aus der univariaten Exponentialfamilie. Enthalten sind damit
insbesondere Regressionsmodelle für binäre
Zielgrößen (Bernoulliverteilung) und
Zählvariablen (Poissonverteilung), aber auch
Regressionsmodelle für nichtnegative Zufallsvariablen
basierend auf der Gammaverteilung. Der Kurs stellt zunächst
einige spezielle generalisierte lineare Modelle vor und bettet diese
anschließend in den allgemeinen Rahmen ein.
- Modelle mit zufälligen Effekten:
- Bei der Analyse von Longitudinaldaten oder
gruppierten Daten ist die Annahme der Unabhängigkeit der
Beobachtungen typischerweise nicht mehr gegeben. Regressionsmodelle mit
zufälligen Effekten erweitern den linearen Prädiktor
linearer und generalisierter linearer Modelle um zufällige,
individuen- bzw. gruppenspezifische Effekte und erlauben damit die
Berücksichtigung von Korrelationen. Der Kurs wird sich im
Wesentlichen auf lineare Modelle mit zufälligen Effekten
beschränken, aber auch kurz auf Erweiterungen für
generalisierte lineare Modelle eingehen.
- Generalisierte additive Modelle:
- In linearen und generalisierten linearen Modellen
wird der Erwartungswert der Zielvariablen basierend auf einem rein
linearen Prädiktor modelliert. Obwohl durch Transformationen
von Kovariablen bereits einfache, nichtlineare Zusammenhänge
beschrieben werden können, sind automatisierte, flexiblere
Alternativen zur Analyse nichtlinearer Zusammenhänge in der
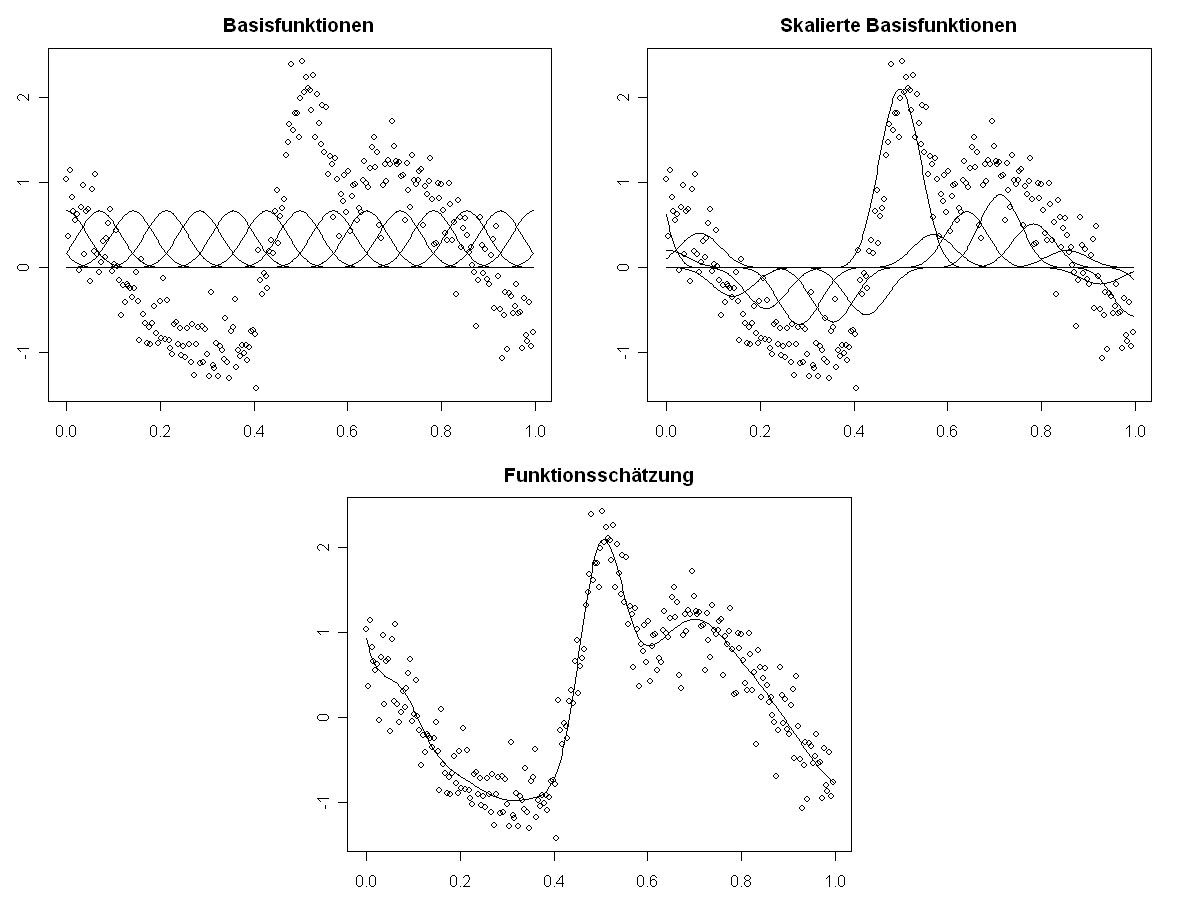
Praxis von besonderem Wert. Generalisierte additive Modelle sind eine
allgemeine Modellklasse zur Untersuchung solcher nichtlinearer
Zusammenhänge. In diesem Kurs wird der besondere Fokus auf der
Modellierung mit Hilfe von Spline-Funktionen und
Penalisierungsansätzen liegen. Eine Reihe von Erweiterungen
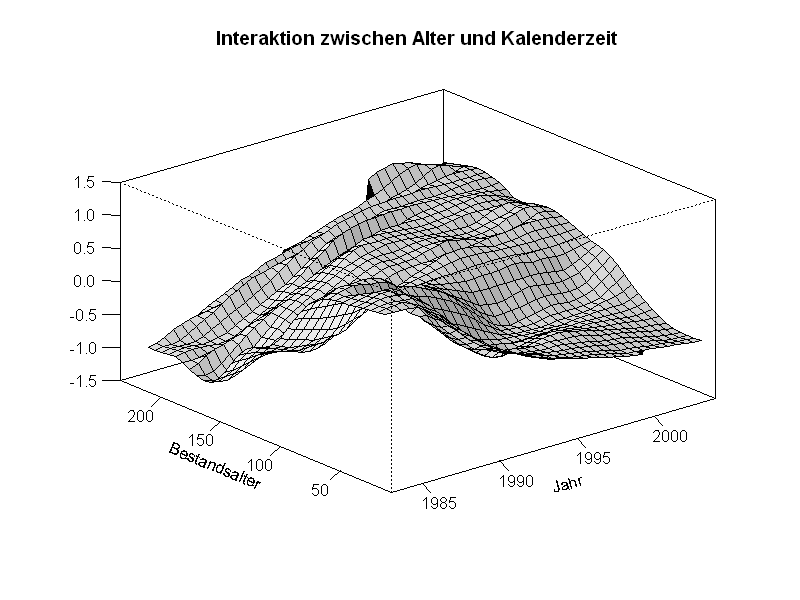
wie die Modellierung von Interaktionen und variierenden Koeffizienten
werden ebenfalls behandelt.
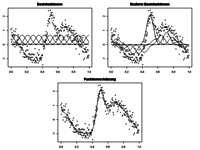 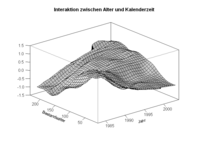
R & Excel: Integration von anspruchsvoller
Statistik in Bürosoftware
- Termin:
- abgesagt
- Dozenten:
- Ao.Univ.Prof.
Dr. Erich Neuwirth, Dipl.-Stat.
Sebastian Kaiser
- Voraussetzungen:
- Verwendung von R, Verwendung von Excel
Inhalt:
Das Excel-Addin
RExcel ermöglicht die Einbettung von R in Excel.
Damit wird es
möglich, anspruchsvolle statistische Methoden mit dem
Benutzer-Interface von Excel einzusetzen.
Diese Einbettung ist auf mehrere Arten möglich:
- Excel als Datencontainer: Rohdaten und
Ergebnisstabellen können einfach zwischen Excel und R
transferiert werden. Kommandos werden über die
Excel-Kommandozeile eingegeben, aber auch Excel kann als Notizblock
für R-Kommandos verwendet werden.
- Excel als Anwendungsmaschine: VBA-Macros, die der
Benutzer gar nicht sehen muss, automatisieren die Verwendung von R als
Excel-Erweiterung. Durch Klicken von Buttons werden R-Programme
ausgeführt. Dadurch wird Excel zu einem einfach bedienbaren
Frontend fuer R, und es wird möglich, R auch nicht
statistische gebildeten Benutzern in Form vorgefertigter statistischer
Anwendungen zur Verfügung zu stellen.
- Worksheet-Funktionen: R kann auch in die
Neuberechnungs-Automatik von Excel eingebettet werden. Damit kann man
Worksheet-Funktionen implementieren, die R verwenden, aber immer dann,
wenn sich Daten ändern, automatisch neu berechnet werden. R
wird also ganz nahtlos als Teil der "Rechenmaschine" in Excel
eingebettet.
Die Teilnehmer lernen in diesem Kurs Beispiele
zu allen drei Einsatzsatzszenarien kennen und erstellen auch kleine
Anwendungen. Softwareinstallation und grundlegende Information
über
die Architektur des Systems (notwendig zur korrekten Installation)
werden ebenfalls behandelt.
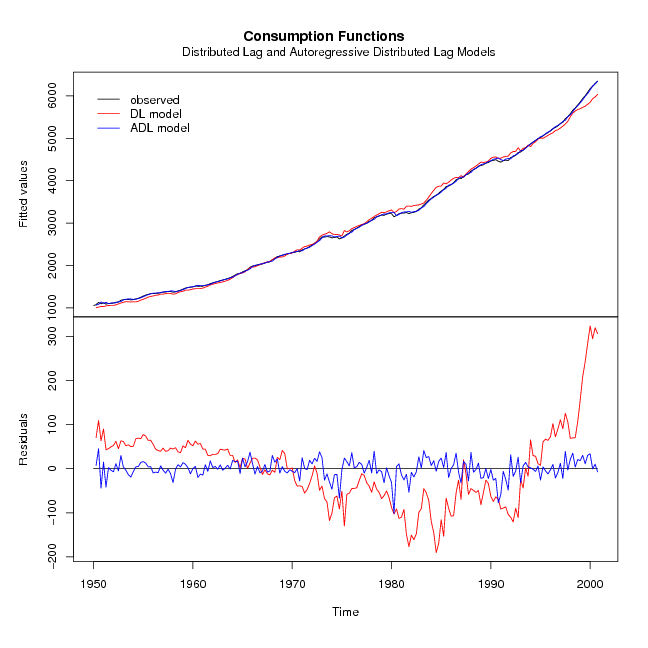
Angewandte Ökonometrie mit R
- Termin:
- Do 10.7.2008, 9-17:30 & Fr 11.7.2008, 9-16
- Dozent:
- Dr. Achim
Zeileis
- Voraussetzungen:
- grundlegende Kenntnis der ökonometrischen
Methoden sowie praktische Erfahrung mit R
Inhalt:
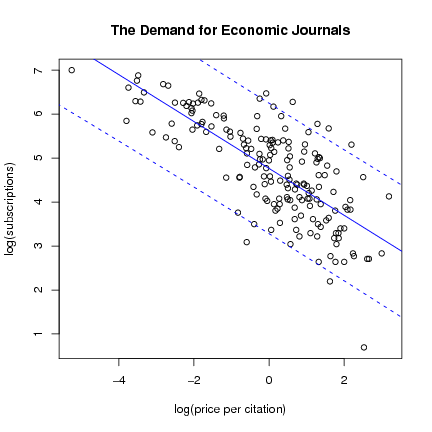
- Lineare Regression für Querschnitts- und
Zeitreihendaten
- Validierung und Diagnostik für
Regressionsmodelle
- Zeitreihen: Werkzeuge, klassische Analyse,
Einheitswurzel/Kointegration, Strukturbrüche
- Ausblick auf weitere Regressionsmodelle: Panel-Daten,
nicht/semi-parametrische Regression, mikroökonometrische
Modelle
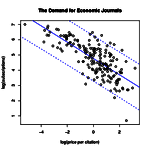 
|