R Anfängerkurs
Inhalt:Dieser Grundkurs richtet sich an Anfänger, die das Werkzeug R zur Analyse und Visualisierung eigener Daten erlernen wollen. Neben Installation und Grundlagen der Bedienung von R wird die praktische Anwendung einfacher deskriptiver statistischer Methoden an Beispielen demonstriert und geübt. Der Kurs umfasst die Themen:
Praktische Datenanalyse mit R
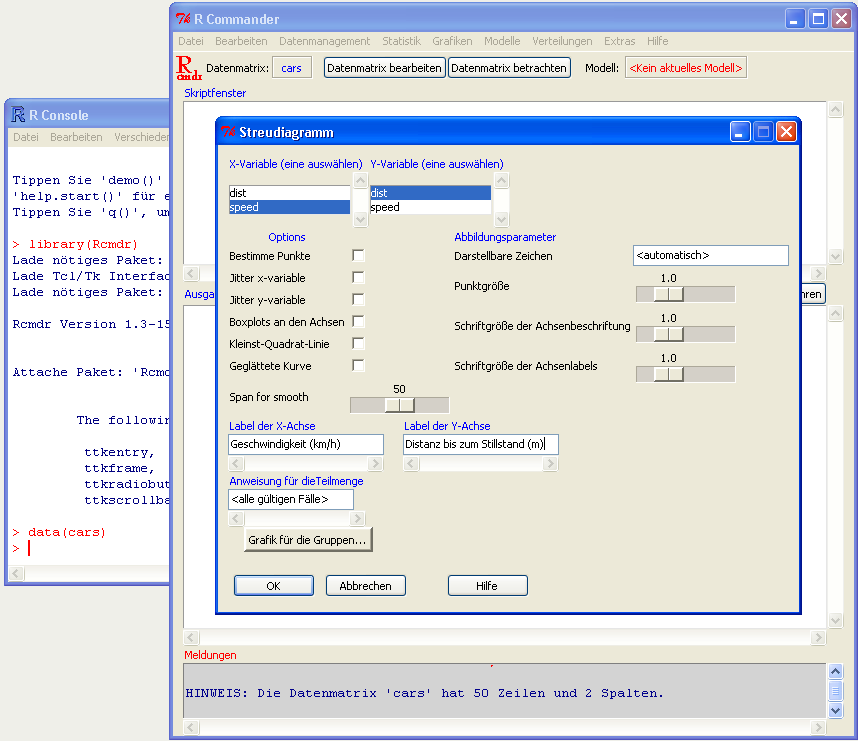
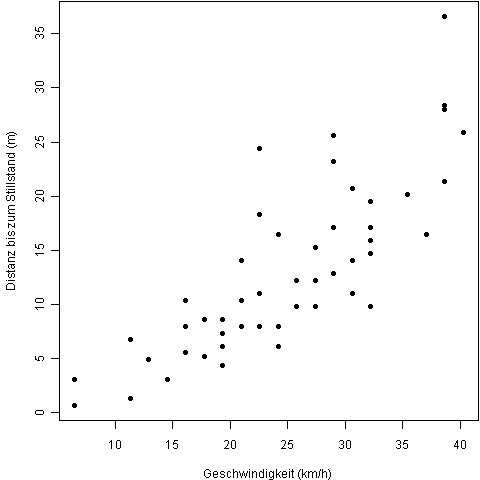
Inhalt:Dieser Kurs zeigt, wie bekannte Standardmethoden der Statistik mit Hilfe von R zur Analyse eigener Daten verwendet werden können. Der Fokus liegt auf den aus Statistik-Einführungsvorlesungen bekannten Verfahren der Visualisierung von Daten, klassischen Hypothesen-Tests (t-Test, Varianzanalyse, ...), nichtparametrischen Verfahren und bedingter Inferenz. Ein weiterer Schwerpunkt ist das lineare Regressionsmodell mit Erweiterungen wie multipler Regression, kategorische Prädiktoren und verallgemeinerte lineare Modelle Alle verwendeten statistischen Verfahren werden zur Auffrischung kurz erklärt.Ziel des Kurses ist es, die aus eher theoretischen Statistik-Vorlesungen bekannten Verfahren in der Praxis an echten Daten anzuwenden. Der Kurs basiert auf dem Buch "A Handbook of Statistical Analysis Using R" von Brian S. Everitt und Torsten Hothorn, erschienen 2006 bei CRC Press (ISBN 9781584885399). Ein Freiexemplar des Buches ist in der Kursgebühr enthalten. Multivariate Statistik mit R
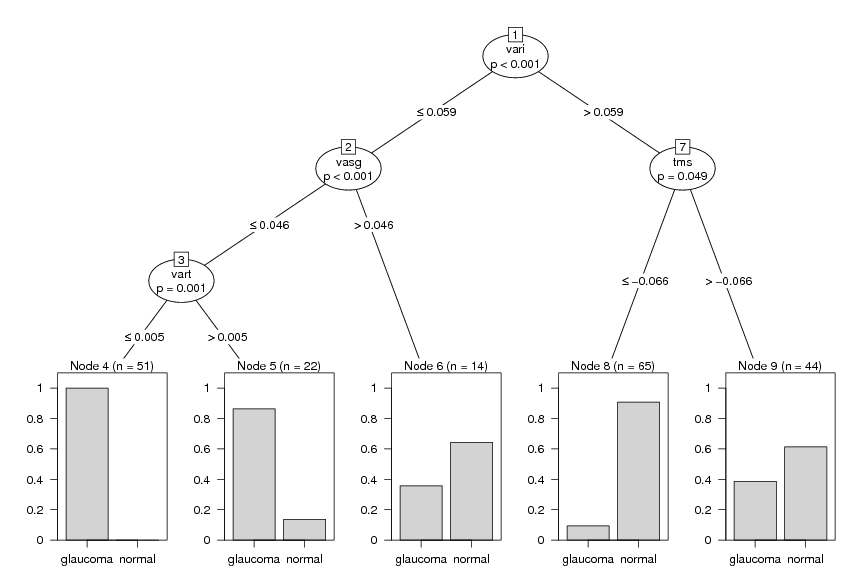
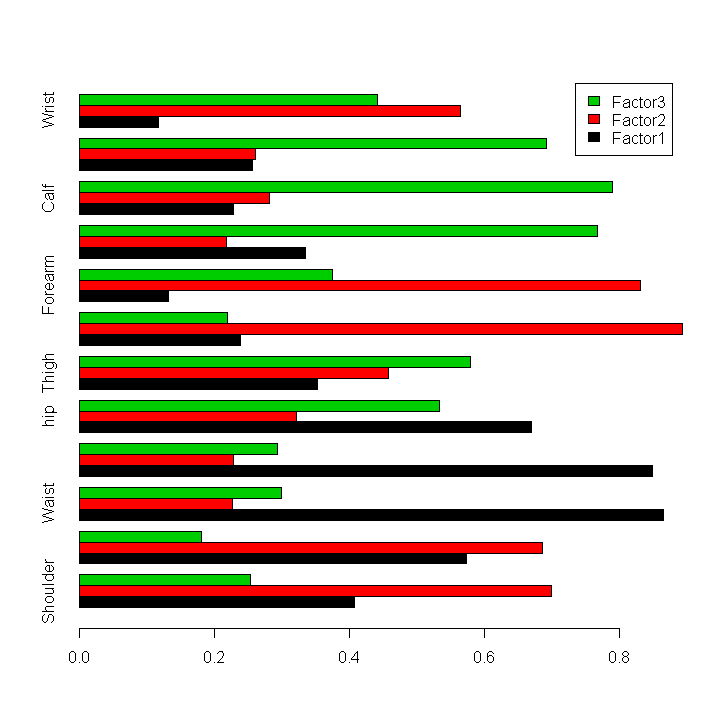
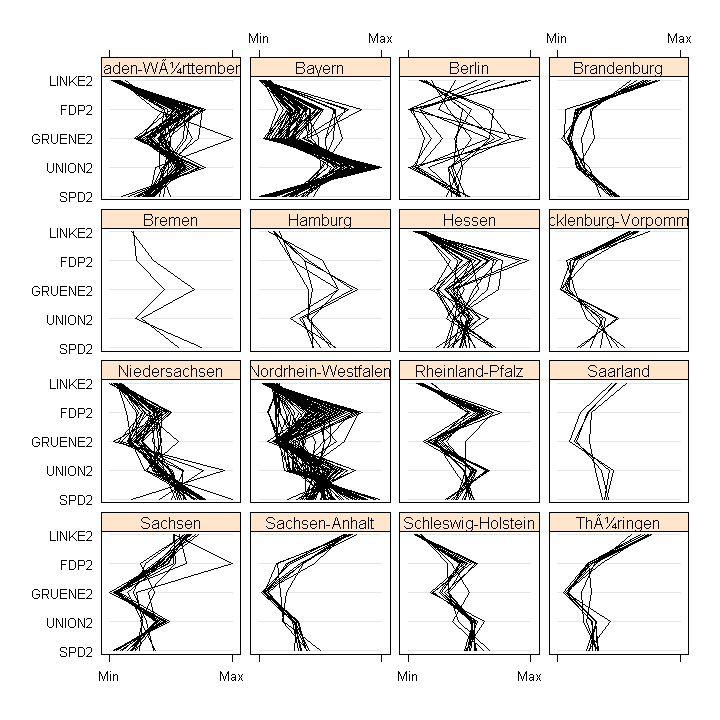
Inhalt:Die multivariate Statistik beschaftigt sich mit dem Auffinden und der Modellierung von Strukturen in höherdimensionalen Datensätzen, wobei "höherdimensional" typischerweise "ab drei" (ohne Schranke nach oben) bezeichnet. Zu Beginn des Kurses werden Methoden zur Visualisierung höherdimensionaler Daten wie Linearprojektionen, parallele Koordinaten, Grand Tour und interaktive Methoden (Linking, Brushing) vorgestellt. Weitere Themen sind Diskriminanzanalyse zur Prognose kategorischer abhängiger Variablen (Klassifikation), und das Auffinden von Gruppen in Daten mit Hilfe der Clusteranalyse. Den Abschluß bilden Dimensionsreduktionverfahren wie Hauptkomponenten- und Faktorenanalyse, die benutzt werden können, um latente Zusammenhangsstrukturen in Daten zu modellieren. Die Theorie aller vorgestellten Methoden wird erklärt und die Anwendung an praktischen Beispielen im EDV-Labor geübt.
Psychometrie mit R
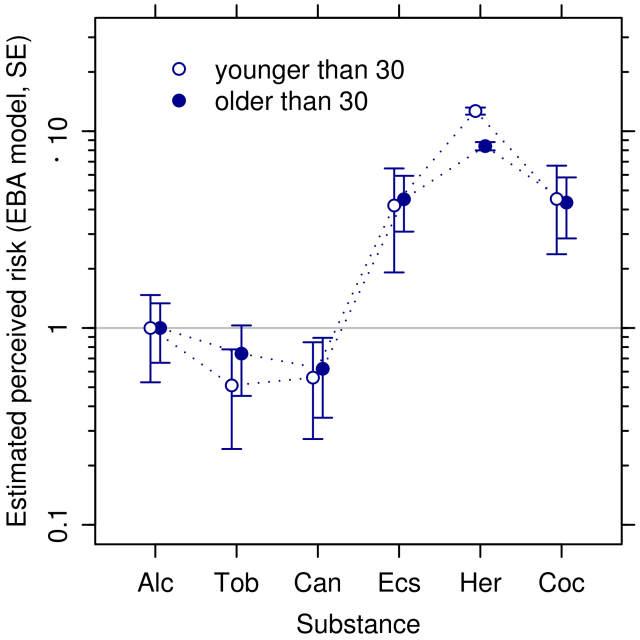
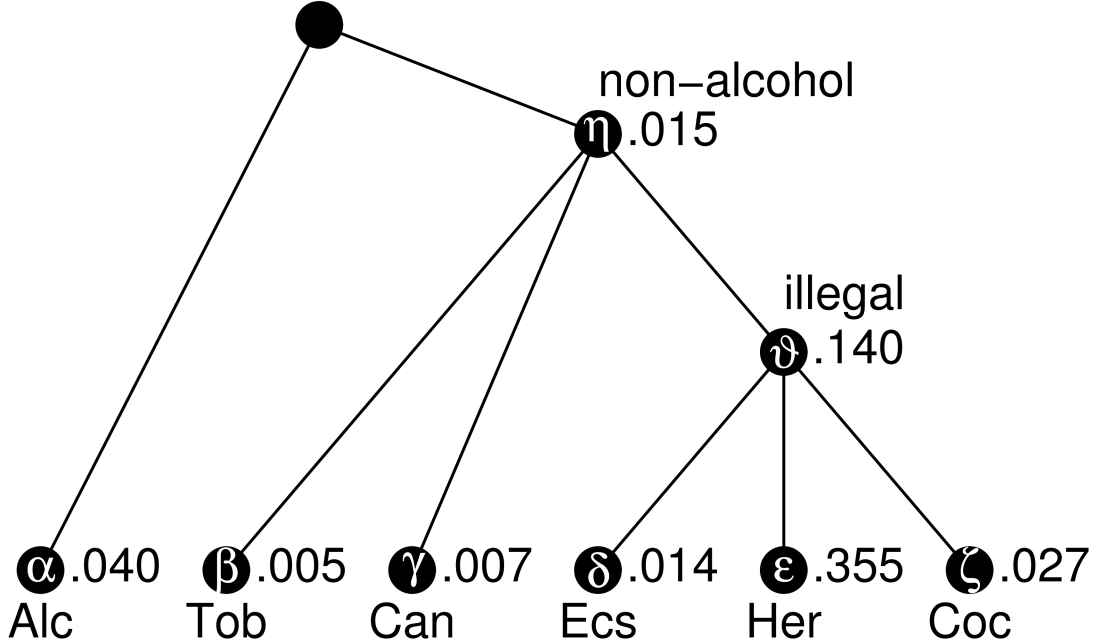
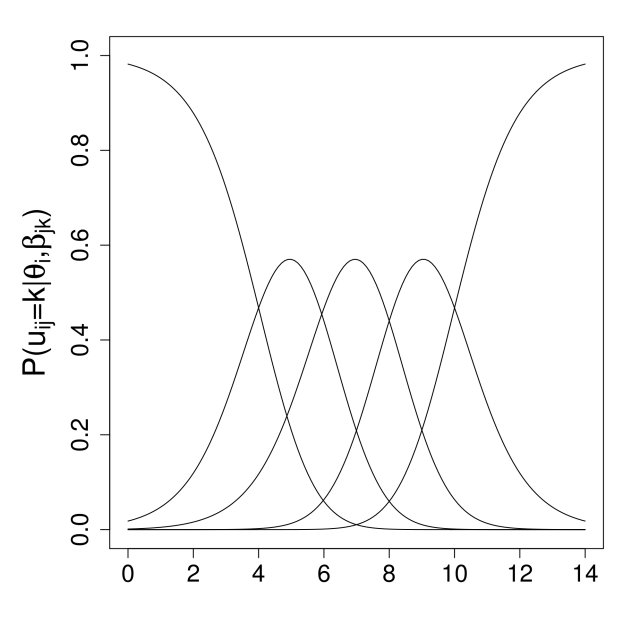
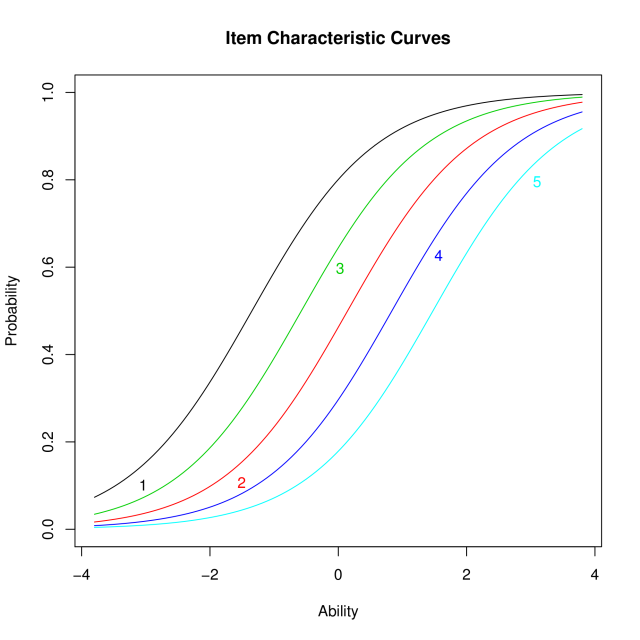
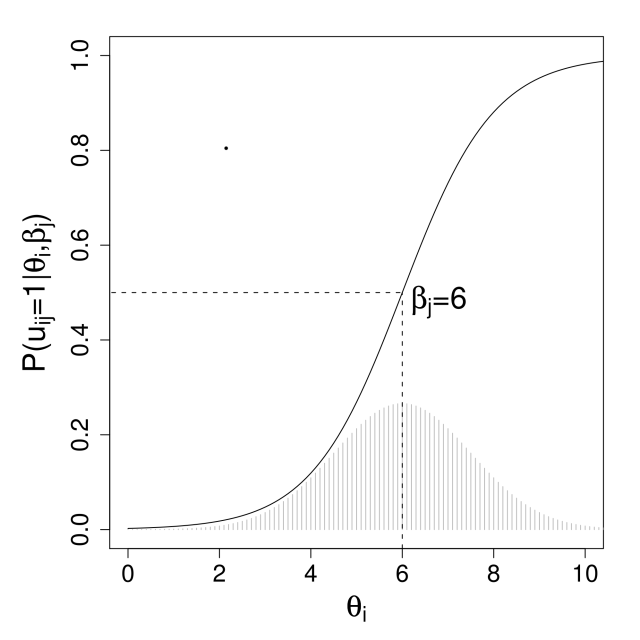
Inhalt:In diesem Kurs werden zwei der zentralen Themengebiete der Psychometrie vorgestellt: die Messung von Personen-Eigenschaften und Fähigkeiten mithilfe der Item-Response-Theorie (IRT) und die Skalierung von Attributen und Präferenzen anhand von Paarvergleichsdaten und probabilistischen Wahlmodellen.Die den Verfahren zugrundeliegenden theoretischen und statistischen Prinzipien und Annahmen werden verständlich eingeführt. Die praktische Anwendung der Verfahren in R wird in mehreren Übungssequenzen behandelt. Der Inhalt des Kurses umfaßt
R Anfängerkurs
Inhalt:Dieser Grundkurs richtet sich an Anfänger, die das Werkzeug R zur Analyse und Visualisierung eigener Daten erlernen wollen. Neben Installation und Grundlagen der Bedienung von R wird die praktische Anwendung einfacher deskriptiver statistischer Methoden an Beispielen demonstriert und geübt. Der Kurs umfasst die Themen:
Machine Learning & Data Mining mit R
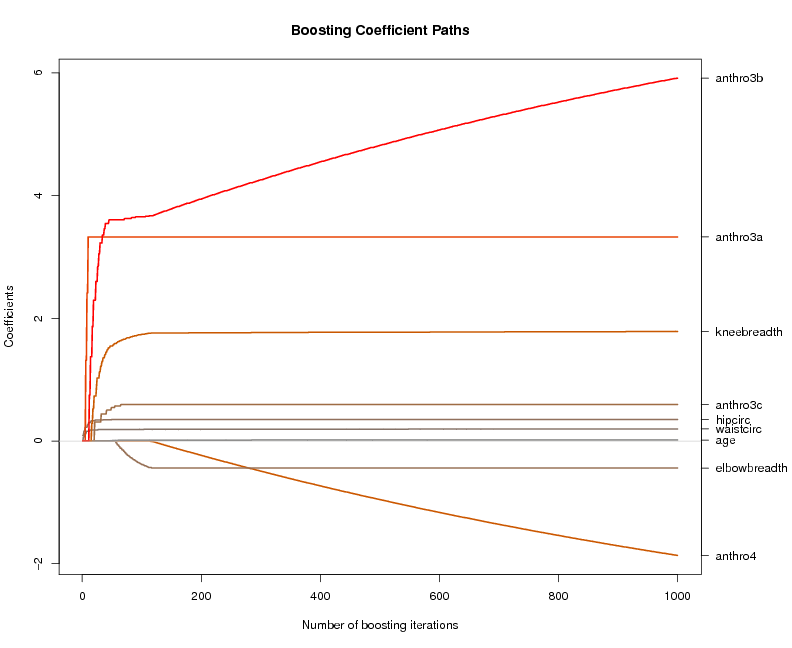
Inhalt:In diesem Kurs werden moderne statistische Verfahren des maschinellen Lernens zur Analyse komplexer Klassifikations- und Regressionsprobleme vorgestellt, die besonders für die Modellierung nicht-linearer Regressionszusammenhänge in hoch-dimensionale Daten geeignet sind. Die zugrundeliegenden Prinzipien der Verfahren werden verständlich eingeführt und illustriert, sowie Besonderheiten herausgehoben.Ein Schwerpunkt ist dabei die Selektion von wenigen relevanten Einflußgrößen aus tausenden von potentiellen Kandidaten, z.B. in der Selektion von genetischen Markern zur Prognose des Krankheitsstatus. Der Hauptteil des Kurses beschäftigt sich mit der Anwendung von in R verfügbaren Werkzeugen anhand von Beispielen aus der Praxis.
|