R Anfängerkurs
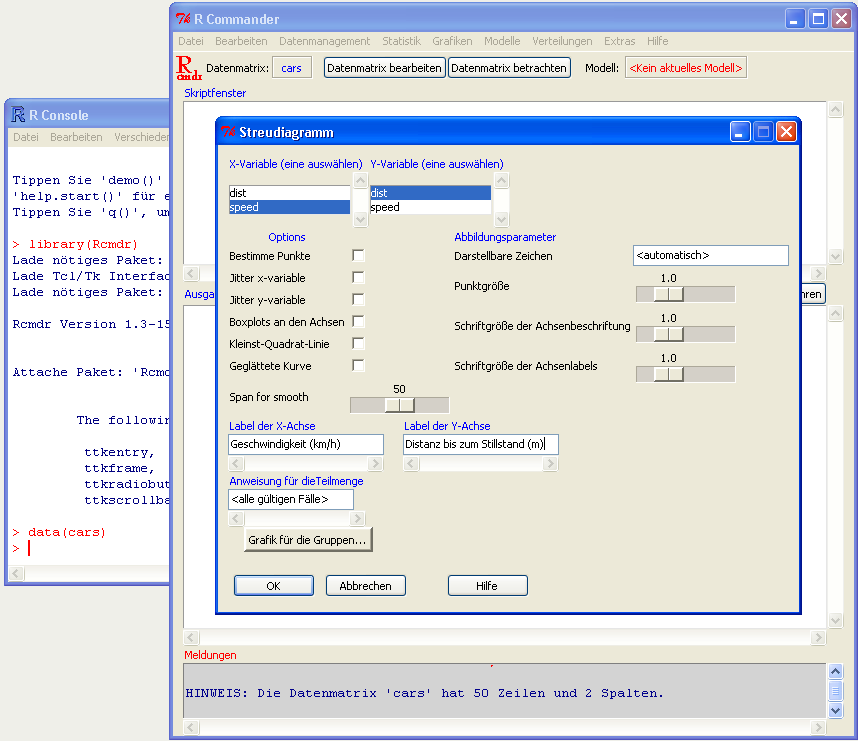
Inhalt:Dieser Grundkurs richtet sich an Anfänger, die das Werkzeug R zur Analyse und Visualisierung eigener Daten erlernen wollen. Neben Installation und Grundlagen der Bedienung von R wird die praktische Anwendung einfacher deskriptiver statistischer Methoden an Beispielen demonstriert und geübt. Der Kurs umfasst die Themen:
     Multivariate Statistik mit R
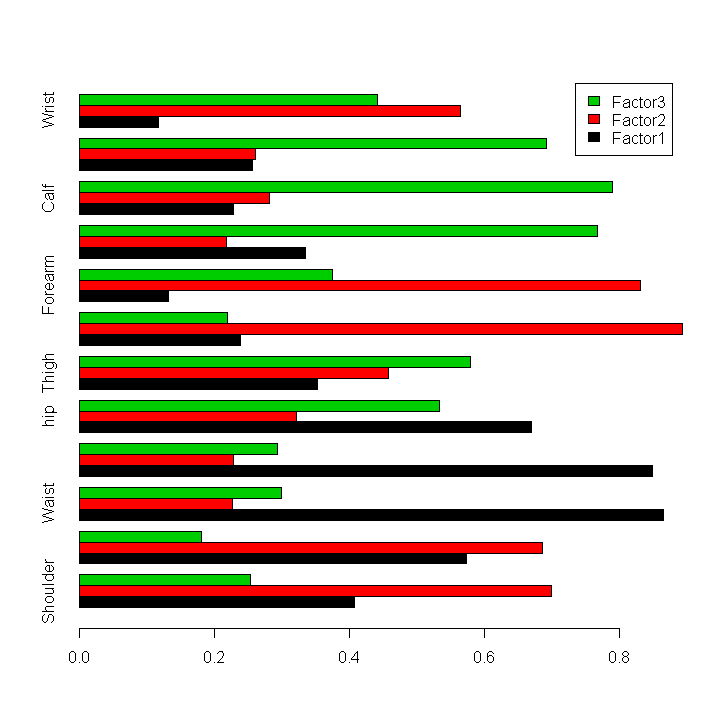
Inhalt:Die multivariate Statistik beschäftigt sich mit dem Auffinden und der Modellierung von Strukturen in höherdimensionalen Datensätzen, wobei "höherdimensional" typischerweise "ab drei" (ohne Schranke nach oben) bezeichnet. Zu Beginn des Kurses werden Methoden zur Visualisierung höherdimensionaler Daten vorgestellt. Weitere Themen sind Diskriminanzanalyse zur Prognose kategorischer abhängiger Variablen (Klassifikation), und das Auffinden von Gruppen in Daten mit Hilfe der Clusteranalyse. Den Abschluß bilden Dimensionsreduktionverfahren wie Hauptkomponenten- und Faktorenanalyse, die benutzt werden können, um latente Zusammenhangsstrukturen in Daten zu modellieren. Die Theorie aller vorgestellten Methoden wird erklärt und die Anwendung an praktischen Beispielen im EDV-Labor geübt. Der Kurs basiert auf dem Buch An Introduction to Applied Multivariate Analysis with R von B. Everitt und T. Hothorn.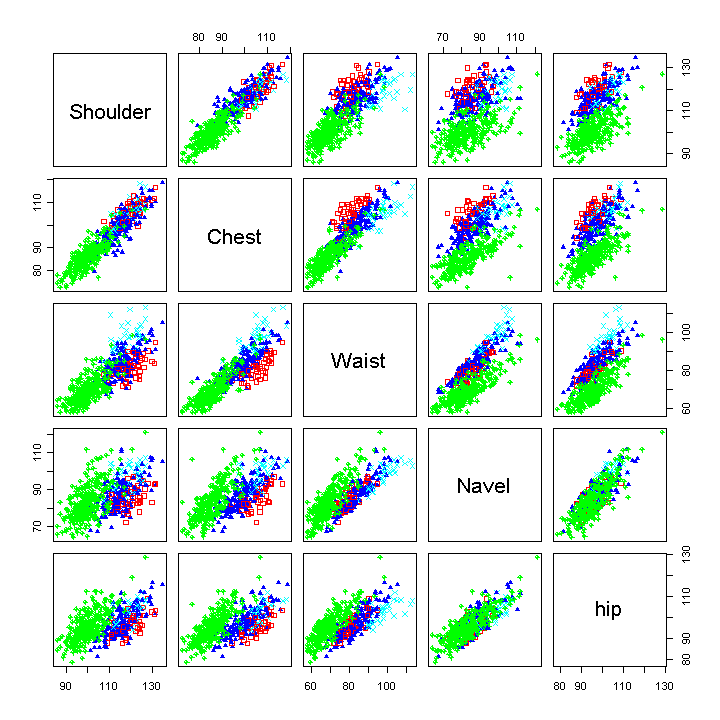  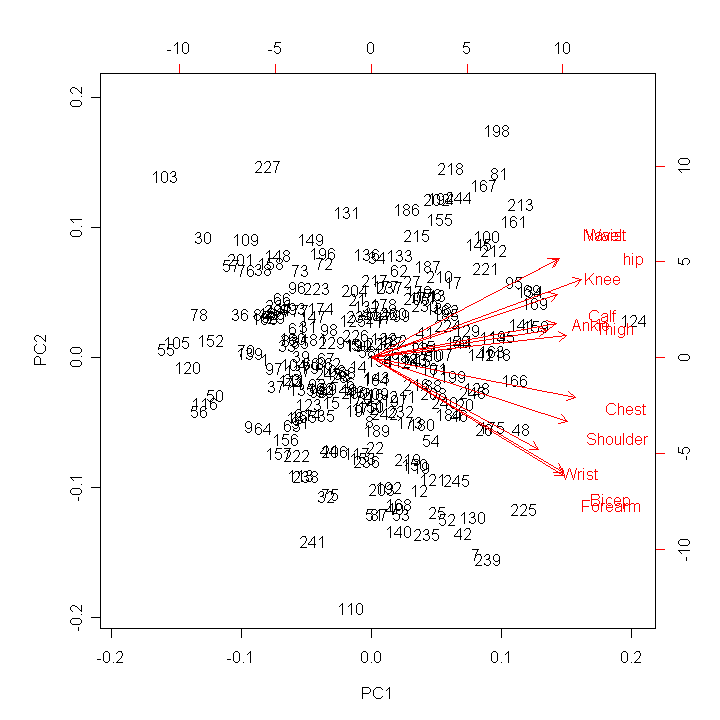  Praktische Datenanalyse mit R
Inhalt:Dieser Kurs wurde für Personen konzipiert, die bekannte Standardmethoden der Statistik mit Hilfe von R zur Analyse eigener Daten verwenden möchten. Themenschwerpunkte sind dabei:
Der Kurs basiert auf dem Buch "A Handbook of Statistical Analysis Using R" von Brian S. Everitt und Torsten Hothorn, erschienen 2006 bei CRC Press (ISBN 9781584885399). Programmieren mit R
Inhalt:Dieser Kurs dient der allgemeinen Vertiefung in R und richtet sich an Teilnehmer, die bereits erste Erfahrungen mit R gesammelt haben (z.B. im Anfängerkurs, oder auch im Selbststudium). Aufbauend auf grundlegenden R-Kenntnissen werden einfache Techniken vermittelt, mittels derer sich das komplexe Werkzeug R leichter und effizienter bedienen lässt. Zudem wird erklärt, wie sich statistische Resultate und Ergebnisse aus R Code automatisch und dynamisch in Berichten einbinden lässt. Themenschwerpunkte sind dabei:
R Anfängerkurs
Inhalt:Dieser Grundkurs richtet sich an Anfänger, die das Werkzeug R zur Analyse und Visualisierung eigener Daten erlernen wollen. Neben Installation und Grundlagen der Bedienung von R wird die praktische Anwendung einfacher deskriptiver statistischer Methoden an Beispielen demonstriert und geübt. Der Kurs umfasst die Themen:
Effizientes und Paralleles Programmieren mit R
Inhalt:Zentrales Thema des Kurses ist der effiziente Einsatz von R für zeitintensive Rechenmethoden und statistische Experimente. Zu Beginn wird eine strukturierte Einführung in die elementaren Techniken des effizienten Programmierens in R gegeben:
Wir werden sicherstellen, dass die Teilnehmer für die Dauer des Kurses auf mindestens einer Hochleistungsrechenumgebung experimentieren und deren technische Details erlernen können. Anvisiert ist hier eine Kooperation mit dem Leibniz Rechenzentrum (LRZ, www.lrz-muenchen.de), so dass dessen Linux-Cluster im Batch-Betrieb genutzt werden kann. Dies erfordert Grundkenntnisse im Umgang mit der Unix-Shell. Deshalb wird von den Teilnehmern erwartet, dass sie sich vor Beginn des Kurses anhand von bereitgestelltem Material selbstständig vorbereiten (Aufwand ca. 2 Stunden). Der Kurs wird in deutscher Sprache gehalten, die Kursmaterialien sind in englischer Sprache verfasst. Maschine Learning & Data Mining mit R
Inhalt:In diesem Kurs werden moderne statistische Verfahren des maschinellen Lernens zur Analyse komplexer Klassifikations- und Regressionsprobleme vorgestellt, die besonders für die Modellierung überwachter, nicht-linearer Zusammenhänge geeignet sind. Die zugrundeliegenden Prinzipien der Verfahren werden für Anfänger verständlich eingeführt und illustriert, sowie Besonderheiten herausgehoben. Der Hauptteil des Kurses beschäftigt sich mit der Anwendung von in R verfügbaren Werkzeugen anhand praktischer Beispiele.Modellierungstechniken, die im Kurs behandelt werden:
Analyse von Finanzdaten mit R
Inhalt:Ziel des Kurses ist es, den TeilnehmerInnen die Anwendung der wichtigsten State-of-the-Art-Techniken zur Analyse von Finanzdaten mit Hilfe von R zu vermitteln. Hierbei handelt es sich zum einen um Modelle der Zeitreihenanalyse, die Risikoprognosen ermöglichen - allen voran die 2003 mit dem Nobelpreis für Wirtschaftswissenschaften prämierten (G)ARCH-Modelle. Zum anderen lernen wir Methoden zur Beschreibung und Modellierung komplexer Abhängigkeitsstrukturen zwischen verschiedenen Wertpapieren innerhalb eines Portfolios kennen. Nach einer kurzen Einführung in die Theorie steht jeweils die praktische Anwendung im Vordergrund. Die Themen im Einzelnen:
Praktische Datenanalyse mit R
Inhalt:Dieser Kurs wurde für Personen konzipiert, die bekannte Standardmethoden der Statistik mit Hilfe von R zur Analyse eigener Daten verwenden möchten. Themenschwerpunkte sind dabei:
Der Kurs basiert auf dem Buch "A Handbook of Statistical Analysis Using R" von Brian S. Everitt und Torsten Hothorn, erschienen 2006 bei CRC Press (ISBN 9781584885399). Unsupervised Statistical Learning mit R
Inhalt:Der Ausdruck "Statistical Learning" bezieht sich auf eine Menge von Methoden zur Erkennung von Strukturen und Zusammenhängen in Datensätzen. Die Verfahren des statistischen Lernens lassen sich in überwachtes Lernen (englisch: supervised learning) und unüberwachtes Lernen (englisch: unsupervised learning) einteilen. Anders als bei Methoden des überwachten Lernens (z.B. bei Regressionsverfahren) gelten für sämtliche Methoden des unüberwachten Lernens, dass die Charakterisierung der Daten ohne eine a-priori Outputgröße ermittelt wird. In diesem Kurs werden die folgenden modernen Verfahren des unüberwachten statistischen Lernens vorgestellt:
Die multidimensionale Skalierung ist ein Bündel von Analysemethoden zur Entdeckung von Strukturen innerhalb von Beobachtungen. Ziel der multidimensionalen Skalierung ist es die Objekte räumlich so anzuordnen, dass die Abstände (Distanzen) zwischen den Objekten im Raum möglichst exakt den erhobenen (Un-)Ähnlichkeiten entsprechen. Um die Interpretation zu erleichtern, wird die erhaltene Konfiguration meist in zwei oder drei Dimensionen dargestellt. Biplots sind graphische Darstellungen von Datenmatrizen, die gleichzeitig Objekte und Variablen in einer Graphik abbilden. Biplots bieten die Möglichkeit der Visualisierung der Zeilen und Spalten einer Datenmatrix, aufbauend auf verschiedenen dimensionsreduzierenden Verfahren, beispielsweise der Hauptkomponentenanalyse oder der multidimensionalen Skalierung. Die Assoziationsanalyse bezeichnet die Suche nach Assoziationsregeln. Diese beschreiben Korrelationen zwischen gemeinsam auftretenden Dingen. Der Zweck einer Assoziationsanalyse besteht darin, Items (Elemente einer Menge, wie z.B. einzelne Artikel eines Warenkorbs) zu ermitteln, die das Auftreten anderer Items innerhalb einer Transaktion implizieren. Die zugrundeliegenden Prinzipien der o.a. Verfahren des unüberwachten statistischen Lernens werden verständlich eingeführt und illustriert. Der Schwerpunkt des Kurses liegt auf der Anwendung von in R verfügbaren Werkzeugen zur Implementierung der Methoden anhand von Beispielen aus der Praxis. Der Kurs findet in deutscher Sprache statt, die Kursunterlagen sind in englischer Sprache verfasst. Wir bitten die Teilnehmer bei der Anmeldung kurz mitzuteilen, zu welchen der oben genannten Themen bereits Vorkenntnisse bestehen. Literatur: - Hastie, T., Tibshirani, R., Friedman, J. (2009): The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2. Auflage, Springer. - Gower, J., Lubbe, S., Le Roux, N. (2011): Understanding Biplots, Wiley. - James, G., Witten, D., Hastie, T., Tibshirani, R. (2013): An Introduction to Statistical Learning with Applications in R, Springer. Praktische Datenanalyse & Programmieren mit R
Inhalt:Dieser Kurs ist eine individuelle Kombination der Kurse "Praktische Datenanalyse mit R" und "Programmieren mit R" und dient der allgemeinen Vertiefung in R. Der Kurs richtet sich an Teilnehmer, die bereits erste Erfahrungen mit R gesammelt haben (z.B. im Anfängerkurs, oder auch im Selbststudium). Aufbauend auf grundlegenden R-Kenntnissen werden einfache Techniken vermittelt, mittels derer sich das komplexe Werkzeug R leichter und effizienter bedienen lässt. Weiterhin werden einige bekannte Methoden aus der Statistik vorgestellt, die zur Analyse eigener Daten verwendet werden können. Alle verwendeten statistischen Verfahren und Programmiertechniken werden zur Auffrischung kurz erklärt, an echten Datenbeispielen motiviert, demonstriert und mit Hilfe von Übungsaufgaben von den Teilnehmern eingeübt. Zudem wird in dem Anwendungsteil des Kurses auch auf die Interpretation der Ergebnisse eingegangen.Aus den folgenden Themenschwerpunkten werden 5-6 Themen durch Mehrheitsentscheid der Teilnehmer und Teilnehmerinnen ausgewählt:
|